前言
在 AI Agent 凭据安全架构思考 一文中,我们讨论了执行层隔离的基本思路。本文将进一步聚焦一个更具体的命题:
当 OpenClaw 拥有丰富的 Skill 生态时,能否同时满足以下三个条件:
- Skill 生态完全兼容——现有工具无需改造
- Skill 凭据对 Agent 完全不可见——Agent 不接触任何明文
- Skill 可以正常工作——功能不受影响
答案是:做不到。
在 OpenClaw 框架下,它们之间存在根本性的互斥关系,无法在同一个系统中同时满足。
OpenClaw 的信任模型
在讨论矛盾之前,先明确 OpenClaw 的安全设计前提。OpenClaw 官方安全文档(docs/gateway/security/index.md)明确采用 personal assistant 信任模型:
Personal assistant trust model: this guidance assumes one trusted operator boundary per gateway. OpenClaw assumes the host and config boundary are trusted.
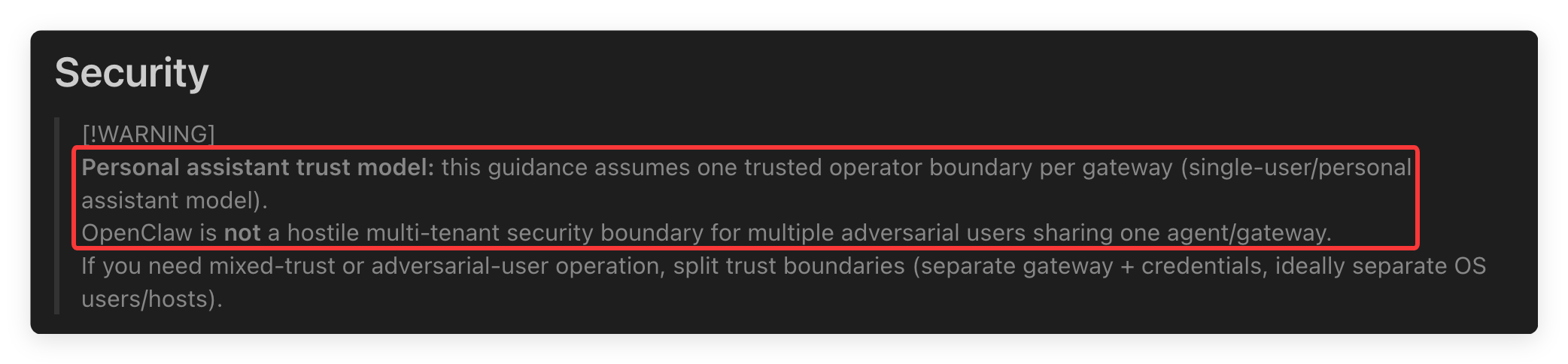
在这个模型下,Agent 被视为 operator 的完全代理人,天然继承凭据访问权限。Agent 接触凭据明文是设计前提。
但这不意味着没有改进空间。问题在于:改进的边界在哪里?
Agent 必须接触的凭据
在讨论"隔离哪些凭据"之前,先厘清"哪些凭据根本不可能隔离"。
flowchart LR
subgraph MustHold["Agent 必须持有的凭据"]
direction TB
LLM["LLM API Key
每次推理必需"]
Channel["通道 Token
Discord / Telegram / QQ
长连接维持"]
WebUI["Gateway 密码
Web UI 认证"]
end
subgraph CanIsolate["Skill 凭据(可隔离)"]
direction TB
Cloud["云 API Key"]
DB["数据库密码"]
SSHKey["SSH Key"]
Internal["用户自定义服务
内部 API / 内部系统"]
end
MustHold -->|"Agent 进程本身就是消费者
无法剥离"| Label1["无法隔离"]
CanIsolate -->|"Agent 只是使用者
不是凭据消费者"| Label2["可以隔离"]
style LLM fill:#B22222,color:#fff
style Channel fill:#B22222,color:#fff
style WebUI fill:#B22222,color:#fff
style Cloud fill:#228B22,color:#fff
style DB fill:#228B22,color:#fff
style SSHKey fill:#228B22,color:#fff
style Internal fill:#228B22,color:#fff
style Label1 fill:#B22222,color:#fff
style Label2 fill:#228B22,color:#fff
为什么下面的三类凭据无法隔离?
| 凭据 | 原因 | 强行隔离的代价 |
|---|---|---|
| LLM API Key | Agent 每次推理都调用 LLM Provider,Key 必须在进程中可用 | 在 Agent 进程前加 LLM 代理(所有推理流量经代理转发),侵入性极强且增加延迟 |
| 通道 Token | 通道运行时与 Gateway 事件循环深度耦合,长连接 Token 必须在进程内 | 将通道运行时拆分为独立进程,属于架构级重构 |
| Gateway 密码 | Web UI 认证,核心功能依赖 | 拆分 Web UI 为独立服务,工程量大且收益低 |
要隔离这些凭据,必须在 Agent 进程内部做代理——在 HTTP 客户端层注入 LLM Key、在 WebSocket 层注入通道 Token,本质上是重写核心通信路径。
这样做代价极高:每增加一层代理就增加一次网络跳转的延迟,且核心路径的任何 bug 都可能导致 Agent 完全不可用。更重要的是,这会对 OpenClaw 的默认架构产生强侵入性——LLM 调用和通道连接是 OpenClaw 的核心运行路径,任何改动都意味着每次 OpenClaw 升级都需要同步维护这些代理逻辑,升级成本和稳定性风险显著增加。对于 personal assistant 场景,这种投入与安全收益不成比例。
因此,凭据隔离的讨论范围限定在 Skill 凭据(云 API Key、数据库密码、SSH Key、用户自定义服务凭据等),而非 Agent 自身运行所需的凭据。
针对 Skill 凭据的四个命题
明确了讨论范围,定义四个希望同时达成的目标:
| 编号 | 命题 | 含义 |
|---|---|---|
| P1 | Agent 不接触凭据明文 | Agent 进程在任何时刻、任何路径上都无法获取 Skill 凭据的明文 |
| P2 | Skill 生态完全兼容 | 现有的 Skill 工具无需改造即可继续使用 |
| P3 | 无需引入执行代理 | Agent 调用 Skill 工具时,不需要经过中间代理 |
| P4 | 代理兼容任意 Skill | 如果引入了执行代理,该代理能无差别执行任何 Skill 操作,不受协议限制 |
不可能四边形
P1(不接触明文)∧ P2(Skill 兼容)∧ P3(无代理)∧ P4(代理通用)= ⊥
四者不可同时成立。三对核心矛盾如下:
flowchart TB
P1["P1: Agent 不接触凭据明文"]
P2["P2: Skill 生态完全兼容"]
P3["P3: 无需引入执行代理"]
P4["P4: 代理兼容任意 Skill"]
P1 -.-|"矛盾① 不改 Skill 工作方式
就无法阻止 Agent 接触凭据"| P2
P1 -.-|"矛盾② 不接触凭据就必须有人替 Agent 执行
不存在第三条路"| P3
P1 -.-|"矛盾③ 代理必须理解协议才能执行
协议空间无限,代理能力有限"| P4
style P1 fill:#B22222,color:#fff
style P2 fill:#1565C0,color:#fff
style P3 fill:#D97706,color:#fff
style P4 fill:#228B22,color:#fff
矛盾 ①:P1(不接触明文)∧ P2(Skill 兼容)— 隔离 vs 兼容
当前 Skill 生态的工作方式:
flowchart LR
LLM["LLM 推理"] -->|"决定调用"| Agent["Agent"]
Agent -->|"① 读取凭据"| Config["配置存储"]
Agent -->|"② 携带凭据调用"| Skill["Skill 工具"]
Skill -->|"③ 返回结果"| Agent
style Agent fill:#B22222,color:#fff
style Config fill:#1565C0,color:#fff
style Skill fill:#228B22,color:#fff
style LLM fill:#5E35B1,color:#fff
步骤 ① ② 都发生在 Agent 进程内。要 P1(不接触明文),必须改变这个流程;要 P2(Skill 兼容),不能改变这个流程。
矛盾 ②:P1(不接触明文)∧ P3(无代理)— 隔离 vs 无代理
flowchart TB
Question["Agent 需要调用 AWS S3
但自己不能接触 AWS Key"]
PathA["路径 A: Agent 自己拿 Key 调用"]
PathB["路径 B: 代理替 Agent 调用"]
PathC["路径 C: ???"]
Question --> PathA
Question --> PathB
Question --> PathC
PathA -->|"违反 P1(不接触明文)"| Fail1["❌ Agent 接触了明文"]
PathB -->|"违反 P3(无代理)"| Fail2["❌ 引入了代理"]
PathC -->|"不存在"| Fail3["❌ 没有第三条路"]
style Question fill:#5E35B1,color:#fff
style Fail1 fill:#B22222,color:#fff
style Fail2 fill:#B22222,color:#fff
style Fail3 fill:#B22222,color:#fff
style PathA fill:#E8E8E8,color:#333
style PathB fill:#E8E8E8,color:#333
style PathC fill:#E8E8E8,color:#333
如果 Agent 不接触凭据(P1),且没有代理(P3),那凭据调用操作没有人来执行。
矛盾 ③:P1(不接触明文)∧ P4(代理通用)— 隔离 vs 通用代理
flowchart LR
Proxy["凭据代理"]
subgraph done["✅ 已适配"]
direction LR
HTTP["HTTP API"]
SQL["数据库"]
end
subgraph todo["🔧 待适配"]
direction LR
SSH["SSH"]
GRPC["gRPC"]
WS["WebSocket"]
Custom1["自定义 A"]
CustomDot["..."]
CustomN["自定义 N"]
end
subgraph future["❌ 未来"]
direction LR
New1["新协议①"]
NewDot["..."]
NewN["新协议∞"]
end
Proxy --> done
Proxy -.->|"持续适配"| todo
Proxy -.-x|"永远追不完"| future
style Proxy fill:#5E35B1,color:#fff
style HTTP fill:#228B22,color:#fff
style SQL fill:#228B22,color:#fff
style SSH fill:#D97706,color:#fff
style GRPC fill:#D97706,color:#fff
style WS fill:#D97706,color:#fff
style Custom1 fill:#D97706,color:#fff
style CustomDot fill:#D97706,color:#fff
style CustomN fill:#D97706,color:#fff
style New1 fill:#B22222,color:#fff
style NewDot fill:#B22222,color:#fff
style NewN fill:#B22222,color:#fff
代理必须理解操作协议才能正确注入凭据并执行调用。协议空间是无限的,所以通用代理在工程上不存在。
矛盾的本质
还原到最底层,只有一个问题:谁在运行时持有 Skill 凭据的明文?
回顾四个命题:
- P1(不接触明文):Agent 进程无法获取 Skill 凭据明文
- P2(Skill 兼容):现有 Skill 工具无需改造
- P3(无代理):调用 Skill 不需要中间代理
- P4(代理通用):代理能无差别执行任意 Skill 操作
flowchart LR
H1["Agent 自己持有"]
H2["Skill 独立进程持有"]
H3["通用凭据代理持有"]
H1 -->|"满足 P2(Skill 兼容)P3(无代理)P4(代理通用)
违反 P1(不接触明文)"| R1["Agent 接触了明文"]
H2 -->|"满足 P1(不接触明文)P4(代理通用,有限)
违反 P3(无代理),可能 P2(Skill 兼容)"| R2["需改造 Skill"]
H3 -->|"满足 P1(不接触明文)
违反 P3(无代理)P4(代理通用)"| R3["协议有限"]
style H1 fill:#D97706,color:#fff
style H2 fill:#1565C0,color:#fff
style H3 fill:#5E35B1,color:#fff
style R1 fill:#B22222,color:#fff
style R2 fill:#D97706,color:#fff
style R3 fill:#B22222,color:#fff
P2(Skill 兼容)、P3(无代理)、P4(代理通用)两两之间并不矛盾——它们可以同时成立,只要放弃 P1。因此严格来说,P1 是唯一的核心冲突点,其余三个命题是围绕 P1 的三方矛盾。
改造层级
在讨论具体方案之前,先定义改造深度的四个层级,后续方案会引用这些层级:
| 层级 | 改造范围 | 含义 |
|---|---|---|
| L0 | 零改动 | 不修改 OpenClaw 代码和配置,通过外挂组件实现 |
| L1 | 改配置 | 修改 OpenClaw 配置文件(如 SecretRef 对接外部 KMS),不改源码 |
| L2 | 改源码 | 修改 OpenClaw 源码(如新增加密 source type、内存管控等) |
| L3 | 改架构 | 重构 OpenClaw 核心架构(如进程拆分、内置凭据代理协议) |
方案探讨
既然四个命题不可同时成立,问题就从"怎么全都要"变成"放弃哪个"。
方案 A:用完即焚 — 放弃 P1(不接触明文)的绝对性
保留: P2(Skill 兼容)、P3(无代理) 放弃: P1 的绝对形式 → 改为"不持久化,仅使用时短暂持有"
flowchart LR
Enc["磁盘加密存储
KMS 信封加密"]
Agent["Agent
短暂持有明文"]
Skill["Skill 工具"]
Agent -->|"调用时实时解密"| Enc
Enc -->|"短暂持有"| Agent
Agent -->|"使用后立即清除"| Skill
style Enc fill:#228B22,color:#fff
style Agent fill:#D97706,color:#fff
style Skill fill:#1565C0,color:#fff
- 凭据在磁盘上加密存储(通过 SecretRef exec 对接 KMS 可实现),配置文件不含明文
- 使用时实时解密,用完立即从内存清除(需适当改造 OpenClaw 源码以支持内存管控)
- 不改 Skill、不引代理、不受协议限制
安全效果: 缩小明文时间窗口,但执行瞬间 Agent 仍接触明文。其中磁盘加密可通过现有 SecretRef exec 机制实现,内存管控需要 L2 级源码改造。
方案 B:外挂式代理 — 放弃 P2(Skill 兼容)
不改 OpenClaw 代码,通过部署 MCP Server 将需要凭据的外部调用从 Agent 进程中剥离。
flowchart LR
Agent["OpenClaw Agent
不持有凭据"]
MCP["ProxyClient
MCP Server"]
CP["ControlPlane
凭据保管库"]
Target["目标服务"]
Agent -->|"MCP tools/call
仅业务参数"| MCP
MCP -->|"请求凭据"| CP
CP -->|"注入凭据"| MCP
MCP -->|"携带凭据执行"| Target
Target -->|"结果"| MCP
MCP -->|"结果"| Agent
style Agent fill:#1565C0,color:#fff
style MCP fill:#228B22,color:#fff
style CP fill:#228B22,color:#fff
style Target fill:#5E35B1,color:#fff
优势:
- OpenClaw 零改动(L0 级),部署即生效
- Agent 完全不接触外部服务凭据(云 API、数据库、SSH)
- 即使 Agent 被提示注入攻击,也无法获取这些凭据
- 对于有标准 SDK 的服务(如 AWS、Azure、GCP),外挂式代理集成更加方便和统一——直接在代理进程中引入官方 SDK,凭据管理和认证逻辑由 SDK 原生处理
劣势:
- 必须引入 MCP 服务,增加了部署复杂度
- 存在绕过风险——Agent 的 exec 工具仍可直接调用目标服务,绕过代理。但可以通过 Skill 配置限制 exec 的权限范围(如 allowlist),或在 L2 改造中禁用特定 Skill 的 shell exec 能力来缓解
- 扩展新工具成本高——每接入一个新的外部服务,都需要在 Proxy 侧开发对应的适配器(理解协议 + 注入凭据 + 执行请求)
- 对用户内部服务不友好——Proxy 适配器是预置的,用户自建的内部服务(自定义 API、内部数据库)需要自行开发适配器或退回明文模式
- 相比协议注入层,集成度更高但耦合度也更高——协议注入层只需抠出认证逻辑单独适配,而外挂式代理需要完整集成 SDK。对于没有标准 SDK 的服务,反而更重
方案 C:协议层注入 — 放弃 P4(代理通用),仅覆盖标准协议
不引入独立的执行代理,而是在 Agent 的出站请求层做 Auth Hook——凭据不存明文,在请求发出的瞬间从外部获取并注入。
flowchart LR
Agent["Agent"]
Hook["Auth Hook Layer"]
KMS["外部 KMS / Vault"]
Target["目标服务"]
Agent -->|"发起请求
(无凭据)"| Hook
Hook -->|"实时获取凭据"| KMS
KMS -->|"返回凭据"| Hook
Hook -->|"注入认证信息
Header / Cookie / SigV4"| Target
Target -->|"结果"| Agent
style Agent fill:#1565C0,color:#fff
style Hook fill:#D97706,color:#fff
style KMS fill:#228B22,color:#fff
style Target fill:#5E35B1,color:#fff
以 HTTP 服务为例:Agent 发出请求时不带 Auth 信息,Auth Hook 层拦截请求,例如从外部 KMS/Vault 获取凭据,注入到 HTTP Header(如 Authorization: Bearer xxx)后转发。
优势:
- Agent 进程内存中不持有凭据明文
- 仅做 Auth 层的 Hook,不代理整个请求执行流程,侵入性低于方案 B
- 对标准 HTTP API 效果好——大部分云服务都走 HTTP,Header 注入规则统一
劣势:
- 需要兼容各种协议——HTTP 注入 Header 相对简单,但 SSH 需要注入密钥、数据库需要注入连接字符串、gRPC 需要注入 metadata。每种协议一套注入逻辑
- 扩展新能力时工作量较重——每新增一种协议的 Auth 方式,都需要开发对应的 Hook
- 对用户内部服务可以有限度支持——比如用户配置"Header 规则模板"(
Authorization: Bearer {{cred}}),由 Hook 层填充。但这只覆盖 HTTP Header 级别的场景,更复杂的认证方式(请求签名、双向 TLS、自定义 Token 交换)仍需定制开发 - 本质上是"薄代理"——虽然不代理执行,但代理了认证,仍然是一个中间层
- 对于有标准 SDK 的服务,集成度不如外挂式代理——协议注入层需要把 SDK 中的认证逻辑抠出来单独适配,而外挂式代理直接集成 SDK 即可
方案对比
| 维度 | A: 用完即焚 | B: 外挂式代理 | C: 协议层注入 |
|---|---|---|---|
| Agent 接触明文 | 执行瞬间短暂接触 | 完全不接触 | 完全不接触 |
| P2(Skill 兼容) | ✅ 零改造 | ❌ 需 MCP 适配 | ⚠️ HTTP 好,其他需开发 |
| P4(代理通用) | ✅ 无限制 | ❌ 适配器有限 | ⚠️ 有限,可扩展 |
| 部署复杂度 | 低 | 中(需部署 MCP) | 中(需部署 KMS + Hook) |
| 绕过风险 | 无(Agent 本就持凭据) | ⚠️ exec 可绕过代理 | ⚠️ exec 可绕过 Hook |
| 用户内部服务支持 | ✅ 原生支持 | ❌ 需自建适配器 | ⚠️ HTTP 可配置,其他受限 |
| 信任模型 | 信任 Agent | 不信任 Agent | 不信任 Agent |
写在最后
这篇文章的目的不是制造悲观,而是澄清边界。
Skill 凭据隔离的核心矛盾不是"能不能做到",而是"愿意放弃什么"。在做架构设计时,最常见的错误是试图同时满足所有命题——既要 Agent 完全不碰凭据,又要现有 Skill 零改造,又要保持隔离方案能适配所有协议。
理解了四者不可同时成立,就可以根据实际威胁模型做出有意识的取舍:
flowchart TB
Start["选择方案"]
Q1{"信任 Agent?"}
Q2{"需要凭据完全隔离?"}
Q3{"目标服务类型?"}
A["方案 A:用完即焚
凭据加密存储 → 短暂解密 → 用完清除
Skill 零改造 · 无代理
执行瞬间仍接触明文"]
B["方案 B:外挂式代理
MCP Server 持有凭据并执行操作
Agent 零接触明文 · 适合标准 SDK 服务
扩展新工具成本高 · 用户内部服务需自建适配器"]
C["方案 C:协议层注入
仅在出站请求 Auth 层注入凭据
HTTP 效果好 · Header 模板支持内部服务
非标协议无法覆盖"]
Start --> Q1
Q1 -->|"✅ 信任"| A
Q1 -->|"❌ 不信任"| Q2
Q2 -->|"轻量隔离即可"| Q3
Q2 -->|"必须完全隔离"| B
Q3 -->|"有标准 SDK 的云服务"| B
Q3 -->|"HTTP 为主的服务"| C
style Start fill:#5E35B1,color:#fff
style Q1 fill:#1565C0,color:#fff
style Q2 fill:#1565C0,color:#fff
style Q3 fill:#1565C0,color:#fff
style A fill:#228B22,color:#fff
style B fill:#D97706,color:#fff
style C fill:#D97706,color:#fff
承认不可能,才是真正设计的开始。
补充讨论
工具输出的上下文泄露
前面的分析聚焦于"Agent 如何获取凭据",但存在一条被忽视的泄露路径:工具的返回值会直接进入 LLM 上下文。
OpenClaw 的工具调用流程是:
flowchart LR
LLM["LLM Provider"] -->|"决定调用工具"| Agent["Agent"]
Agent -->|"执行工具"| Tool["MCP / Skill 工具"]
Tool -->|"tool result"| Agent
Agent -->|"上下文(含 tool result)
经公网发送"| LLM
style LLM fill:#B22222,color:#fff
style Tool fill:#228B22,color:#fff
style Agent fill:#1565C0,color:#fff
MCP 工具和内置 Skill 工具的输出都会作为 tool result 拼接到对话上下文中,随下一次推理请求发送给 LLM Provider。这意味着即使 Agent 本身不持有凭据,工具返回值中意外包含的凭据片段仍可能泄露到 LLM Provider。
典型场景:
- 数据库查询返回的错误信息中包含连接字符串
- HTTP 响应 header 中带回了 Auth Token
- SSH 命令的 debug 输出包含密钥指纹
- MCP Server 的错误日志泄露了凭据片段
这对三个方案的影响:
| 方案 | Agent 主动获取凭据 | 工具输出泄露凭据 |
|---|---|---|
| A 用完即焚 | ⚠️ 执行瞬间接触 | ⚠️ 可能发生 |
| B 外挂式代理 | ✅ 完全不接触 | ⚠️ MCP 输出仍可能泄露 |
| C 协议层注入 | ✅ 完全不接触 | ⚠️ Hook 层输出仍可能泄露 |
方案 B 和 C 切断了 Agent 主动获取凭据的能力,但无法完全防止凭据通过工具输出流向 LLM Provider。 这需要额外的输出过滤/脱敏机制来防护。
沙箱执行:第三条路?
文中的分析框架假设 Agent 和 Skill 在同一进程空间。但现代方案(如 Deno 权限模型、Firecracker 微虚拟机、WASM 沙箱)可以在不引入"代理"的前提下实现进程级隔离。这是否能打破不可能四边形?
答案是否定的。沙箱改变了隔离的技术手段,但不改变逻辑矛盾。 沙箱内的代码仍然需要凭据才能执行——要么从外部注入(等于引入了代理),要么沙箱自己持有(等于 Skill 独立进程)。沙箱让方案 B(外挂式代理)或方案 C(协议层注入)的工程实现更干净,但 P1 与 P2/P3/P4 的逻辑冲突依然存在。
P1 是唯一的核心冲突点
前面的不可能四边形展示了三对矛盾(P1∧P2、P1∧P3、P1∧P4),但没有讨论 P2∧P3、P2∧P4、P3∧P4 之间的组合。实际上这三对并不矛盾——P2(Skill 兼容)、P3(无代理)、P4(代理通用)两两之间可以同时成立,只要放弃 P1(不接触明文)。因此严格来说,P1 是唯一的核心冲突点,其余三个命题是围绕 P1 的三方矛盾。
多用户场景下的凭据粒度
本文的分析基于 OpenClaw 当前的单 operator 信任模型。但在多用户场景(如一个 Telegram bot 服务多人)下,凭据粒度应该是什么?是 per-operator(每个 OpenClaw 实例一套凭据)还是 per-user(每个终端用户一套凭据)?
这个问题本文不展开,但它直接影响凭据隔离方案的设计——per-user 粒度的凭据隔离,复杂度远高于 per-operator。这是一个值得后续深入探讨的方向。